고정 헤더 영역
상세 컨텐츠
본문
728x90
스키마[SCHEMA]
테이블, 뷰, 인덱스 등의 데이터베이스 객체들의 집합[메타데이터들의 집합]
→ 스키마들이 모여 데이터베이스를 구축
- 데이터베이스에서 테이블을 작성해 구축해나가는 작업을 "스키마 설계"라고 함
→ 스키마 안에서 테이블을 정의
→ 데이터의 개체, 관계, 속성 3요소를 정의 - 스키마는 데이터 사전에 저장됨
테이블[Table]
데이터베이스에서 데이터들을 저장해두는 공간
- 데이터베이스를 사용하기 위해서는 테이블을 먼저 생성해야함
- 테이블에 생성되는 칼럼이름과 데이터 타입을 입력
→ 칼럼 이름은 영문, 한글, 숫자 모두 가능 - 칼럼에 대한 제약 조건이 있는 경우, CONSTRAINT를 이용해 추가 가능
- 기본키를 지정할 때는 "칼럼명 테이터타입 PRIMARY KEY"를 입력
→ "칼럼명 데이터타입 NOT NULL"으로 먼저 테이블 생성 후 "ALTER TABLE 테이블명 ADD CONSTRAINT 기본키칼럼명 PRIMARY KEY (기본키로 설정할 컬럼명);"도 가능 - 다른 테이블을 참조할 때는 "참조할칼럼명 데이터타입 REFERENCES 현테이블명(칼럼명) ON조건절"
→ "ON DELETE CASCADE"는 참조한 모든 데이터 삭제
→ "ON DELETE SET NULL"은 참조한 칼럼의 값이 NULL값을 가짐 - SELECT 문을 활용한 테이블 생성[CTAS: Create Table ~ As Select ~ FROM ~]
→ 기존 테이블을 이용하므로 칼럼별로 데이터 유형을 다시 재정의 하지 않아도 되는 장점
→ 기존 테이블의 제약조건 중에 NOT NULL만 새로운 복제 테이블에 적용
→ 기본키, 고유키, 외래키, CHECK 등의 다른 제약 조건은 없어짐
(제약조건을 추가하기 위해서는 ALTER TABLE 기능을 사용해야 함)
테이블명 생성시 주의사항
| 1. 객체를 의미할 수 있는 적절한 이름 사용 |
| 2. 가능한 단수형을 사용 |
| 3. 테이블명은 다른 테이블의 이름과 중복되지 않아야 함 |
| 4. 한 테이블 내에서는 칼럼명이 중복되게 지정될 수 없음 |
| 5. 테이블명과 칼럼명은 반드시 문자로 시작해야 함 |
| 6. 사전에 정의한 예약어[Reseved Word]는 사용할 수 없다. |
| 7. A~Z, a~z, 0-9, _, $, #만 사용 가능 [특수문자 사용 불가] |
※ 기본적으로 테이블명이나 칼럼명은 대문자로 만들어짐
뷰[VIEW]
테이블로부터 유도된 가상의 테이블을 "뷰"라고 함
- 실제 데이터를 가지고 있지 않음
→ 단지 정의만 가지고 있으며, 실행 시점에 질의를 재작성해 수행 - 테이블을 참조해서 원하는 칼럼만을 조회
→ 참조한 테이블이 변경되면 뷰도 변경됨
→ 특정 칼럼만 조회시켜 보안성을 향상시킴 - Data Dictionary에 SQL문 형태로 저장하되 실행 시에 참조됨
- 한번 생성된 뷰는 변경할 수 없음[변경하고 싶으면 삭제 후 재생성해야 함]
→ CREATE VIEW문을 사용해 뷰 생성
→ ALTER문을 사용해 뷰를 변경할 수 없음
→ SELECT문을 사용해 일반 테이블처럼 뷰 조회 가능 - DROP VIEW를 사용하면 뷰 삭제 [참조했던 테이블이 삭제된는 것은 아님]
→ "DROP VIEW 뷰이름 RESTRICT;"옵션은 다른 곳에서 뷰를 참조하고 있을 경우 삭제가 취소됨
→ "DROP VIEW 뷰이름 CASCADE;"옵션은 뷰를 참조하는 다른 뷰나 제약조건까지 모두 삭제 - 뷰에 대한 입력, 수정, 삭제할 때는 제약이 있음
| 뷰의 장점 | 뷰의 단점 |
| 하나의 테이블에 여러 개의 뷰 생성 가능 특정 칼럼만 조회 가능[보안 기능] 데이터 관리가 간단 → 테이블 구조 변경시에도 뷰를 사용하는 응용 프로그램 변경할 필요 없음[독립성] SELECT문이 간단[편리성] |
독자적인 인덱스 생성 불가 삽입, 수정, 삭제 연산에 제약 데이터 구조 변경 불가 |
뷰의 종류
| 정적 뷰[Static View] | 동적 뷰[Dynamic View] |
| 일반적인 뷰 서브쿼리의 칼럼을 메인쿼리에서 사용 불가 |
인라인 뷰 인라인뷰 칼럼을 메인쿼리에서 사용 가능 |
Inline View
SQL문이 실행될 때만 임시적으로 생성[일회성]되는 동적인 뷰
(ex> FROM절 안에 서브쿼리문[SELECT문 등]을 사용)
- WHERE절과 함께 사용 못함
→ WHERE절을 사용하는 것은 "Nested Subquery"라고 함
→ SELECT 메인쿼리 FROM 인라인뷰 WHERE 서브쿼리; - 인라인 뷰에 SELECT문을 사용하면 특정 테이블의 전체 데이터가 아닌 일부 데이터를 먼저 추출 가능
→ 일반적으로 인라인 뷰를 통해 가져온 일부 데이터에 별칭을 부여
ex> ~~~ FROM (SELECT DEPTNO, DNAME FROM DEPT) D WHERE 조건~~~~~
→ 대량의 데이터를 다룰 때 용이하게 사용
→ 인라인뷰를 많이 사용하면 가독성이 떨어지기 때문에 WITH절을 사용하기도 함
728x90
인덱스[Index]
자주 검색되는 컬럼[where 조건식에 자주 언급되는 필드]에 부여하는 것[책갈피와 같은 역할]
- CREATE INDEX 문을 사용하여 인덱스 생성
- 데이터 조회시 가장 효과적으로 처리될 수 있도록 접근경로를 제공
→ 삽입, 삭제, 갱신의 경우, 오히려 부하를 가중시킴
(단, 인덱스를 구성하는 칼럼 이외의 데이터가 UPDATE될 때는 인덱스로 인한 부하가 발생하지 않음) - 인덱스를 스캔하여 테입르로 데이터를 찾아가는 방식을 랜덤 엑세스라고 함
→ 랜덤 엑세스는 부하가 크기 때문에 대량의 데이터를 읽을 때 인덱스 스캔보다 테이블 전체 스캔이 유리할 수 있음 - 뷰(View)와 달리 데이터 저장 공간이 따로 필요함
- Equal조건과 between조건이 함께 있는 경우, 인덱스는 값의 범위에 따라 일정하게 정렬되야 하므로 Equal조건으로 조회되는 칼럼이 가장 앞에 나오고 범위조회하는 유형의 칼럼이 그 다음에 오도록 하면 인덱스 이용 효율을 높일 수 있음
→ PK순서에 따른 성능 개선 - 테이블에 만들 수 있는 인덱스 수는 제한이 없으나 너무 많이 만들면 오히려 성능부하 발생
→ 하나의 테이블에 여러 개의 인덱스 생성 가능
→ 하나의 인덱스를 여러 개의 칼럼으로 구성 가능 - 데이터 입력/삭제/수정 시 인덱스도 같이 변화
→ 입력/삭제/수정이 자주 일어나는 테이블에서는 오버헤드가 발생할 수 있으므로 인덱스 사용에 주의!!!
→ 외래키가 설계되어 있지만 인덱스가 없는 상태에서는 입력/삭제/수정의 부하가 덜 생김 - 테이블을 생성할 때, 기본키[PK]는 자동으로 인덱스 생성
→ 외래키[FK]는 자동으로 인덱스가 생성되지 않으므로 수동으로 인덱스를 생성해줘야 함
인덱스의 구조
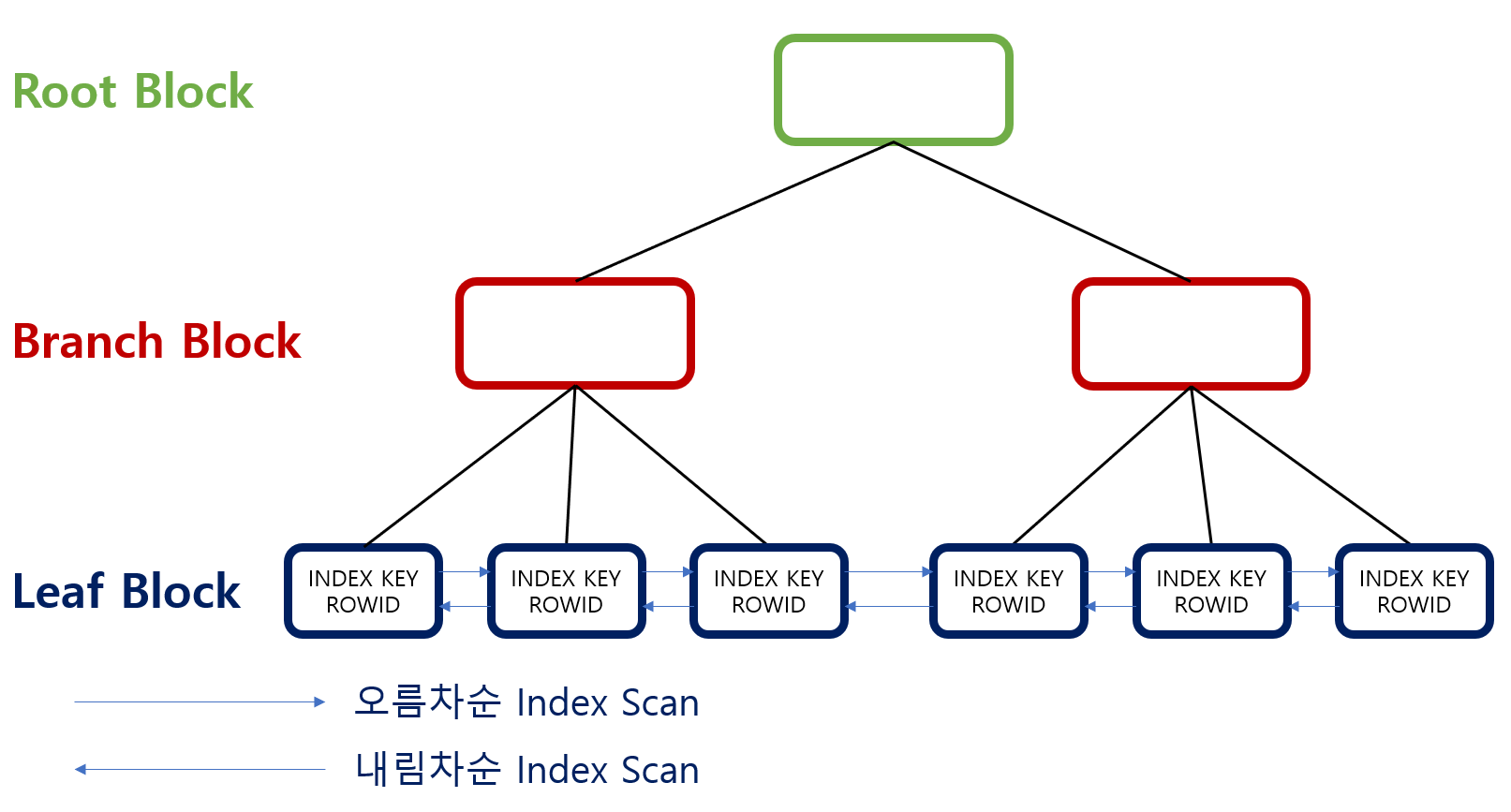
- INDEX구조는 Root Block, Branck Block, Leaf Block으로 구성
Root Block : 인덱스 트리 가장 상위에 있는 노드
Branch Block : Root Block과 Leaf Block을 연결하는 노드
Leaf Block : 인덱스 트리 가장 하위에 있는 노드 [INDEX KEY와 ROWID로 구성]
※ Leaf Block의 INDEX KEY는 정렬되어 저장되어 있음
※ Leaf Block은 Double Linked List형태로 되어 있어 양방향 탐색이 가능 - 인덱스 데이터는 인덱스를 구성하는 칼럼의 값으로 정렬을 수행
→ 오름차순[ASC] 혹은 내림차순[DESC] 탐색 가능
인덱스의 종류
- INDEX의 종류에는 B-Tree Index, Hash Index Fractal-Tree Index 등이 있음
- 일반적으로 데이터베이스 테이블에서는 균형 잡힌 트리구조의 B*Tree구조를 많이 사용
→ B*Tree구조의 내부 알고리즘까지는 알 필요가 없음
→ 하지만 그 구조를 이용할 때 정렬되어 있는 특징을 알아두면 좋은 데이터 모델 설계 가능
(이 특징에 따라 설계에 반영해야 할 요소에 대해서는 반드시 알고 있어야 함) - INDEX를 기본 인덱스와 보조 인덱스로 나누기도 함
| 기본 인덱스[Primary Key Index] | 보조 인덱스[Secondary Index] |
| 고유한 키 값들만 나타남 | 중복된 키 값들이 나타날 수 있음 → UNIQUE INDEX의 경우, 중복 데이터 입력 불가 |
| NULL값이 나타날 수 없음 |
728x90
'자격증 > SQLD' 카테고리의 다른 글
| [개미의 걸음 SQLD 1과목] 데이터 모델링 요소 ① 엔터티(Entity) with 인스턴스 (0) | 2020.12.05 |
|---|---|
| [개미의 걸음 SQLD 1과목] 데이터 모델링 표기법(ERD) (0) | 2020.12.04 |
| [개미의 걸음 SQLD 1과목] 데이터 모델링의 이해 (0) | 2020.12.03 |
| [개미의 걸음 SQLD 1과목] 데이터베이스 구조② 3층 스키마(3-Level Schema) (0) | 2020.12.02 |
| [개미의 걸음 SQLD 들어가기 전] 데이터베이스 기초 (0) | 2020.11.30 |





댓글 영역