고정 헤더 영역
상세 컨텐츠
본문
728x90
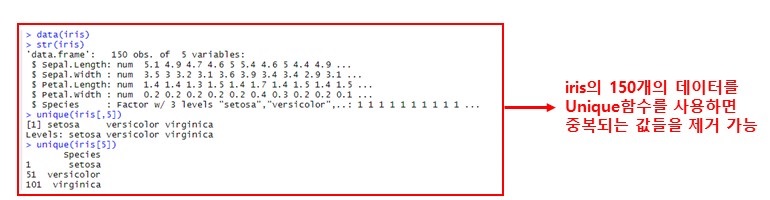
unique( ) 함수
중복되는 값들을 제거할 때 사용
unique(x, incomparables= FALSE, ...)
| Arguments | 설명 |
| x | 벡터, 데이터 프레임, 배열, NULL |
| incomparables | 비교할 수 없는 값의 벡터 FALSE로 지정할 경우 모든 값들을 비교할 수 있다는 의미 |
| fromLast | 중복이 마지막에서부터 고려되는지 아닌지를 논리 값으로 알려줌 기본은 FALSE |
| nmax | unique item들의 최대값을 알려줌 |
| MARGIN | 고정된 배열[array]의 margin 하나의 정수값을 가짐 |
duplicated( ) 함수
중복되는 값들을 제거할 때 사용
duplicated(x, incomparables=FALSE, ...)
| Arguments | 설명 |
| x | 벡터, 데이터 프레임, 배열, NULL |
| incomparables | 비교할 수 없는 값의 벡터 FALSE로 지정할 경우 모든 값들을 비교할 수 있다는 의미 |
| fromLast | 중복이 마지막에서부터 고려되는지 아닌지를 논리 값으로 알려줌 기본은 FALSE |
| nmax | unique item들의 최대값을 알려줌 |
| MARGIN | 고정된 배열[array]의 margin 하나의 정수값을 가짐 |
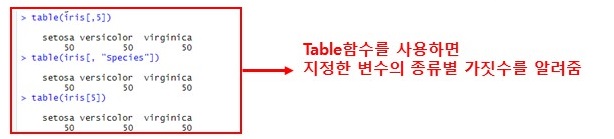
table()함수
중복되는 값들이 몇 개씩 있는지 알려주는 함수
728x90
'자격증 > ADsP' 카테고리의 다른 글
| [개미의 걸음 ADsP 3과목] R에서의 조건문[if, ifelse, switch] (0) | 2020.09.02 |
|---|---|
| [개미의 걸음 ADsP 3과목] Apply 계열함수 (0) | 2020.09.01 |
| [개미의 걸음 ADsP 3과목] subset()함수 (0) | 2020.07.31 |
| [개미의 걸음 ADsP 3과목] paste(), strsplit(), substr(), sub(), gsub(), nchar() (0) | 2020.07.30 |
| [개미의 걸음 ADsP 3과목] str()함수 & head()함수와 tail()함수 & class()함수 (0) | 2020.07.29 |





댓글 영역